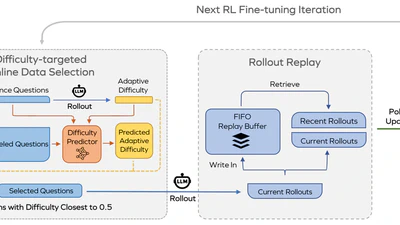
Improving Data Efficiency for LLM Reinforcement Fine-tuning Through Difficulty-targeted Online Data Selection and Rollout Replay
Reinforcement learning (RL) has become an effective approach for fine-tuning large language models (LLMs), particularly to enhance their reasoning capabilities. However, RL …
yifan-sun